Какой вес, двигатель и размер у Лада Приора Хетчбек(ВАЗ 2172)
Лада Приора изначально производилась в четырех вариациях кузова: универсал, седан и хэтчбек (в том числе хэтчбек-купе). Однако наибольшую жизнеспособность, что вполне очевидно, имеют только два типа кузова: седан и хэтчбек, поскольку универсал пользуется не таким потребительским интересом, и в настоящий момент Приоры с таким кузовом больше не производятся. К слову, ВАЗ собирался производить Приору и в кузове кабриолет, но от этой идеи отказались, т.к. в нашей стране эта машина просто не найдет покупателя.
А вот седаны и хэтчбеки – самые востребованные варианты, и вечные конкуренты в деле привлечения покупателя, которые периодически перетягивают на себя канат лидерства продаж в зависимости от модных тенденций, класса автомобиля, марки, практических и эстетических представлений потребителей. Сейчас мы попытаемся разобраться, какими особенностями и преимуществами обладает Лада Приора с кузовом хэтчбек в пяти- и трехдверном (купейном) исполнении.
Двигатели на Ладе Приоре хэтчбек
На 5-дверный хэтчбек ВАЗ 2172, выпускавшийся с 2007 года, устанавливается три двигателя с разной номинальной мощностью, объемом 1596 куб.см:
- Восьмиклапанный 81-сильный мотор, выдающий максимальную скорость 172 км/ч при расходе горючего 7,6 литра на каждые 100 км. при езде в смешанном режиме. Это наименее экономичный из всех приоровских двигателей, хотя и самый дешевый. В настоящее время Приоры им больше не комплектуются;
- 16-клапанный, 89-сильный, способный разогнать машину до 176 км/ч. Потребление топлива в смешанном цикле чуть ниже, а именно – 7,3 л/100 км;
- 98 лошадиных сил: этот 16-клапанный мотор разгонял хэтчбек до 183 км/ч, а в смешанном цикле потреблял 7,4 л/100 км;
3-дверный хэтчбек-купе до 2013 года снабжался только одним мотором – 98 л/с, который придавал этому автомобилю те же технические характеристики, что и его 5-дверному собрату.
Двигатель Приоры Хэтчбек после рестайлинга 2013 года
В 2013 создатели Приоры решили обновить ее дизайн, улучшить эргономику и дооснастить автомобиль согласно требованиям времени, вследствие чего из комплектации убрали 81-сильный и 89-сильный мотор. Вместо них устанавливаются новые 16-клапанные двигатели, хотя и прежнего объема:
Вместо них устанавливаются новые 16-клапанные двигатели, хотя и прежнего объема:
- на 98 л/с, дающий максимальную скорость 183 км/ч, разгон до «сотни» – за 11,5 сек, и потребляющий 6,9 литра топлива на 100 км;
- 106-сильный, обладающий теми же скоростными характеристиками, но незначительно снижающий потребление горючего (до 6,8 литра АИ-95).
Объем багажника лады приора хэтчбек: размер и характеристики
Среди всех Приор хэтчбек имеет самый маленький объем багажника – 360 литров против 430 у седана и 444 в универсальном кузове. Конечно же, багажник любого хэтчбека всегда меньше, чем у того же автомобиля в кузове седан. Однако, 360 литров – это много или мало?
Это число не является предельно малым или предельно большим показателем для хэтчбеков, поэтому придется сопоставить его с аналогичными характеристиками других авто. Например, багажник хэтчбека Приора всего на 10 литров меньше, чем у Hyundai Solaris и на 29 литров меньше, чем KIА Rio, но обладает куда большим объемом, чем багажники Renault Sandero и Ford Fiesta. В этом отношении 360-литровый багажник считается вместительным, и уже по этому признаку хозяйственные качества автомобиля можно считать хорошими.
В этом отношении 360-литровый багажник считается вместительным, и уже по этому признаку хозяйственные качества автомобиля можно считать хорошими.
Вообще, современные легковые автомобили оснащаются багажниками, объемом от 300 до 500 литров, если не учитывать сугубо спортивные или полугрузовые машины с кузовом «универсал», которые пользуются небольшим потребительским интересом. Поэтому багажник хэтчбека Приора можно считать средним по емкости. И если разработчики изначально ставили бы перед собой задачу создать хэтчбек с более вместительным багажником, то им бы пришлось увеличивать габариты авто, выйдя за пределы заданного класса, ценового сегмента, или убрать задний диван.
Если 360 литров кому-то мало, то вместимость Приоры можно увеличить, сложив спинки заднего сиденья или убрав его полностью.
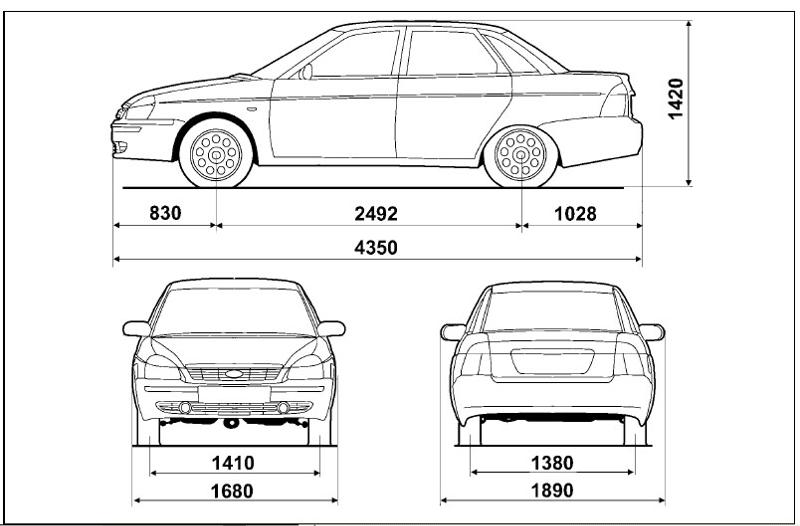
Габаритные размеры Лады Приоры Хэтчбек
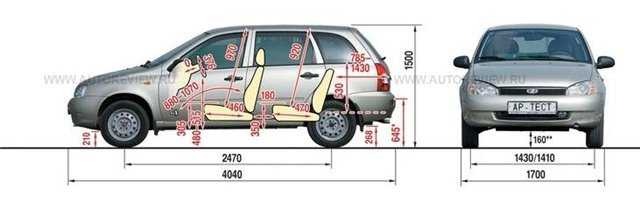
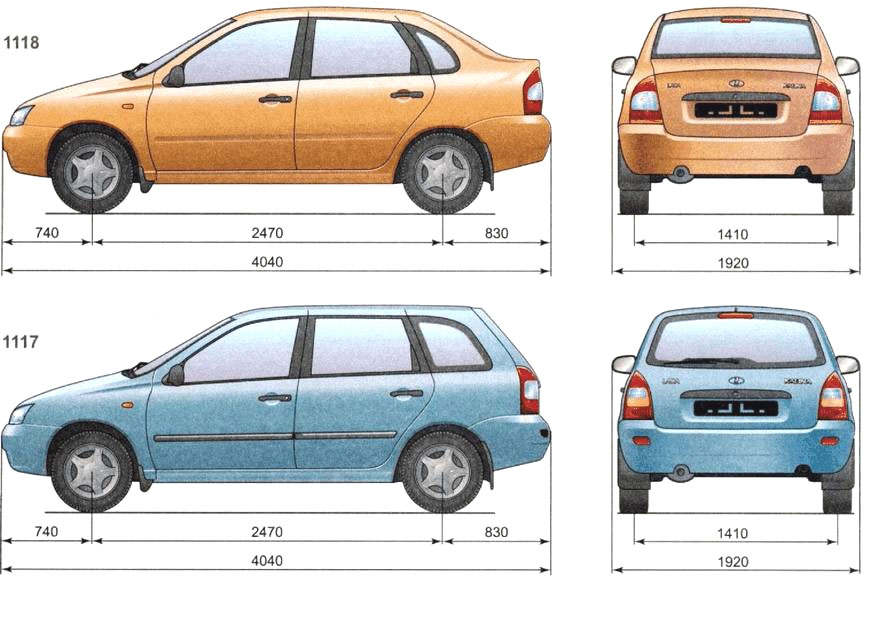
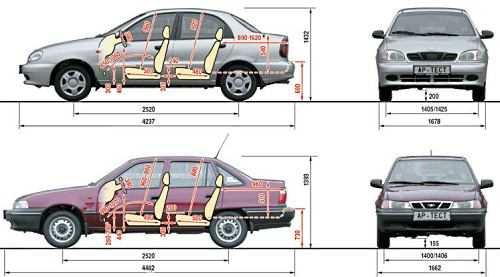
Хэтчбек Приора имеет наименьшие габариты по длине против всех остальных кузовных исполнений. Его длина – 4240 мм в 5-дверном кузове, и 4210 – в 3-дверном кузове купе..jpg) Высота при этом представляет собой промежуточную позицию между низким седаном и высоким универсалом, и равняется 1435 мм.
Высота при этом представляет собой промежуточную позицию между низким седаном и высоким универсалом, и равняется 1435 мм.
Ширина же хэтчбека ничем не отличается от тех же показателей других кузовов, и составляет 1680 мм.
Дорожный просвет – 165 мм, хотя в комплектации Приора-спорт он несколько уменьшен, но в таком варианте этот автомобиль уже снят с производства.
Вес хэтчбека Лада Приора (ВАЗ 21723)
Снаряженная масса хэтчбека ВАЗ 21723 составляет:
- 1088 кг – выпуска до 2013 года. Здесь учитывается, что автомобиль имеет полное оснащение, заправлен полностью, и управляется водителем, вес которого 75 кг. Пассажиры и груз при этом не перевозятся;
- В 2013 году после рестайлинга снаряженная масса стала достигать 1185 кг.
Надо сказать, что полная масса (т.е. максимальный вес автомобиля с полной загрузкой, при котором возможна его эксплуатация) после рестайлинга осталась прежней, а именно – 1578 кг. Это означает, что грузовые возможности хэтчбека после рестайлинга сократились примерно на 100 кг, несмотря на прежний размер багажника.
Чем хорош Лада Приора в кузове хэтчбек?
Ответ на этот вопрос лежит в плоскости того, какими вообще достоинствами обладает такая кузовная вариация.
Во-первых, это более спортивный и динамичный вид, который предпочитает молодой покупатель, даже с учетом того, что седан выглядит солиднее.
Во-вторых, компактный размер и самая короткая колесная база, благодаря которым в городских условиях легче маневрировать и устраиваться на стоянку. Выше мы уже описали габариты хэтчбека.
В-третьих, отсутствие выступающей кормы, которая создает трудности при парковке и движении задним ходом.
В-четвертых, широкий багажный проем (несмотря на то, что у седана Приоры багажник по объему больше), позволяющий уложить габаритные грузы.
Таким образом, хэтчбек Приора – это прекрасный выбор для тех, кто не слишком обременяет себя насущными проблемами, предпочитая уделять время простым жизненным радостям. Это автомобиль для езды, а не для перевозки, которые по достоинству оценят молодые автолюбители, спортсмены, и те, кто не собирается стареть.

Размеры Лада Приора, вес и клиренс
Размеры, вес, клиренс
Евгений Мосензов
Send an email
06.04.2022
0 410 10 минут
Размеры, вес и клиренс автомобиля Лада Приора. Наведены основные поколения и комплектации модели, а так же возможные изменения в пределах одной генерации.
Генерации Lada Priora:
- 1 поколение 2013-2015 (21728, хэтчбек, 3DR, ресталийнг)
- 1 поколение 2013-2015 (2172, хэтчбек, 5DR, ресталийнг)
- 1 поколение 2013-2015 (2171, универсал, ресталийнг)
- 1 поколение 2013-2018 (2170, седан, ресталийнг)
- 1 поколение 2010-2013 (21728, хэтчбек, 3DR)
- 1 поколение 2008-2014 (2172, хэтчбек, 5DR)
- 1 поколение 2008-2013 (2171, универсал)
- 1 поколение 2007-2014 (2170, седан)
Иногда покупая автомобиль, для многих очень важную роль играет размер кузова, клиренс и масса. Автомобиль с низким дорожным просветом будет некстати для загородных поездок или вылазки на пикник. Короткий так же не самый лучший для семейных поездок, так как багажник обычно маленький и не вместительный. Автомобиль Lada Priora предложили в кузове универсал, седан и хэтчбек. По информации производителя, длина модели Лада Приора, в зависимости от кузова и комплектации, составляет от 4210 до 4350 мм, а вес от 1088 до 1185 килограмм. Клиренс Lada Priora 165 мм.
Автомобиль с низким дорожным просветом будет некстати для загородных поездок или вылазки на пикник. Короткий так же не самый лучший для семейных поездок, так как багажник обычно маленький и не вместительный. Автомобиль Lada Priora предложили в кузове универсал, седан и хэтчбек. По информации производителя, длина модели Лада Приора, в зависимости от кузова и комплектации, составляет от 4210 до 4350 мм, а вес от 1088 до 1185 килограмм. Клиренс Lada Priora 165 мм.
Размеры и масса Lada Priora 2013 3DR, 1 поколение, хэтчбек, ресталийнг, 21728
Модель производилась с 10.2013 по 02.2015.
| Комплектация | Размер, мм | Вес, кг | Клиренс, мм |
| Норма 21728-01-041 | 4210 x 1680 x 1435 | 1185 | 165 |
| Стандарт 21728-00-040 | 4210 x 1680 x 1435 | 1185 | 165 |
| Стандарт 21728-01-040 | 4210 x 1680 x 1435 | 1185 | 165 |
| Норма 21728-02-041 | 4210 x 1680 x 1435 | 1185 | 165 |
| Спорт 21728-12-047 | 4243 x 1680 x 1435 | 1185 | 165 |
Размеры и масса Lada Priora 2013 5DR, 1 поколение, хэтчбек, ресталийнг, 2172
Модель производилась с 10. 2013 по 02.2015.
2013 по 02.2015.
| Комплектация | Размер, мм | Вес, кг | Клиренс, мм |
| Люкс 21725-33-043 | 4210 x 1680 x 1435 | 1185 | 165 |
| Норма 21725-31-055 | 4210 x 1680 x 1435 | 1185 | 165 |
| Норма 21725-31-057 | 4210 x 1680 x 1435 | 1185 | 165 |
| Норма 21725-31-075 | 4210 x 1680 x 1435 | 1185 | 165 |
| Люкс 21725-33-051 | 4210 x 1680 x 1435 | 1185 | 165 |
| Люкс 21725-33-053 | 4210 x 1680 x 1435 | 1185 | 165 |
| Норма 21725-31-059 | 4210 x 1680 x 1435 | 1185 | 165 |
| Люкс 21725-33-056 | 4210 x 1680 x 1435 | 1185 | 165 |
| Норма 21723-31-043 | 4210 x 1680 x 1435 | 1185 | 165 |
| Норма 21723-31-044 | 4210 x 1680 x 1435 | 1185 | 165 |
| Норма 21723-31-045 | 4210 x 1680 x 1435 | 1185 | 165 |
| Норма 21723-31-047 | 4210 x 1680 x 1435 | 1185 | 165 |
| Норма 21723-31-049 | 4210 x 1680 x 1435 | 1185 | 165 |
| Люкс 21723-33-046 | 4210 x 1680 x 1435 | 1185 | 165 |
| Норма 21723-31-054 | 4210 x 1680 x 1435 | 1185 | 165 |
| Норма 21723-31-057 | 4210 x 1680 x 1435 | 1185 | 165 |
| Норма 21723-32-054 | 4210 x 1680 x 1435 | 1185 | 165 |
Размеры и масса Lada Priora 2013, 1 поколение, универсал, ресталийнг, 2171
Модель производилась с 10. 2013 по 02.2015.
2013 по 02.2015.
| Комплектация | Размер, мм | Вес, кг | Клиренс, мм |
| Люкс 21715-33-043 | 4340 x 1680 x 1508 | 1185 | 165 |
| Норма 21715-31-055 | 4340 x 1680 x 1508 | 1185 | 165 |
| Норма 21715-31-057 | 4340 x 1680 x 1508 | 1185 | 165 |
| Норма 21715-31-075 | 4340 x 1680 x 1508 | 1185 | 165 |
| Люкс 21715-33-051 | 4340 x 1680 x 1508 | 1185 | 165 |
| Люкс 21715-33-053 | 4340 x 1680 x 1508 | 1185 | 165 |
| Люкс 21715-33-056 | 4340 x 1680 x 1508 | 1185 | 165 |
| Норма 21715-31-059 | 4340 x 1680 x 1508 | 1185 | 165 |
| Норма 21713-31-044 | 4340 x 1680 x 1508 | 1185 | 165 |
| Норма 21713-31-045 | 4340 x 1680 x 1508 | 1185 | 165 |
| Норма 21713-31-047 | 4340 x 1680 x 1508 | 1185 | 165 |
| Люкс 21713-33-046 | 4340 x 1680 x 1508 | 1185 | 165 |
| Норма 21713-31-054 | 4340 x 1680 x 1508 | 1185 | 165 |
| Норма 21713-31-057 | 4340 x 1680 x 1508 | 1185 | 165 |
| Норма 21713-32-054 | 4340 x 1680 x 1508 | 1185 | 165 |
Размеры и масса Lada Priora 2013, 1 поколение, седан, ресталийнг, 2170
Модель производилась с 10. 2013 по 02.2015.
2013 по 02.2015.
| Комплектация | Размер, мм | Вес, кг | Клиренс, мм |
| Люкс 21705-33-043 | 4350 x 1680 x 1420 | 1185 | 165 |
| Норма 21705-31-055 | 4350 x 1680 x 1420 | 1185 | 165 |
| Норма 21705-31-057 | 4350 x 1680 x 1420 | 1185 | 165 |
| Норма 21705-31-075 | 4350 x 1680 x 1420 | 1185 | 165 |
| Люкс 21705-33-051 | 4350 x 1680 x 1420 | 1185 | 165 |
| Люкс 21705-34-051 | 4350 x 1680 x 1420 | 1185 | 165 |
| Люкс 21705-41-055 | 4350 x 1680 x 1420 | 1185 | 165 |
| Люкс 21705-41-057 | 4350 x 1680 x 1420 | 1185 | 165 |
| Норма 21705-41-055 | 4350 x 1680 x 1420 | 1185 | 165 |
| Норма Climate 21705-41-057 | 4350 x 1680 x 1420 | 1185 | 165 |
| Норма White Edition 21705-45-057 | 4350 x 1680 x 1420 | 1185 | 165 |
| Норма Black Edition 21705-44-057 | 4350 x 1680 x 1420 | 1185 | 165 |
| Норма Climate 21705-41-058 | 4350 x 1680 x 1420 | 1185 | 165 |
| Comfort 21705-42-058 | 4350 x 1680 x 1420 | 1185 | 165 |
| Image 21705-45-058 | 4350 x 1680 x 1420 | 1185 | 165 |
| Люкс 21705-33-053 | 4350 x 1680 x 1420 | 1185 | 165 |
| Норма 21705-31-059 | 4350 x 1680 x 1420 | 1185 | 165 |
| Люкс 21705-33-056 | 4350 x 1680 x 1420 | 1185 | 165 |
| Норма 21705-31-058 | 4350 x 1680 x 1420 | 1185 | 165 |
| Стандарт 21702-30-040 | 4350 x 1680 x 1420 | 1185 | 165 |
| Стандарт 21702-40-050 | 4350 x 1680 x 1420 | 1185 | 165 |
| Норма 21703-31-043 | 4350 x 1680 x 1420 | 1185 | 165 |
| Норма 21703-31-044 | 4350 x 1680 x 1420 | 1185 | 165 |
| Норма 21703-31-045 | 4350 x 1680 x 1420 | 1185 | 165 |
| Норма 21703-31-049 | 4350 x 1680 x 1420 | 1185 | 165 |
| Норма 21703-31-047 | 4350 x 1680 x 1420 | 1185 | 165 |
| Люкс 21703-33-046 | 4350 x 1680 x 1420 | 1185 | 165 |
| Норма 21703-31-054 | 4350 x 1680 x 1420 | 1185 | 165 |
| Норма 21703-31-057 | 4350 x 1680 x 1420 | 1185 | 165 |
| Норма 21703-32-054 | 4350 x 1680 x 1420 | 1185 | 165 |
Размеры и масса Lada Priora 2010 3DR, 1 поколение, хэтчбек, 21728
Модель производилась с 03. 2010 по 09.2013.
2010 по 09.2013.
| Комплектация | Размер, мм | Вес, кг | Клиренс, мм |
| 1.6 MT Люкс 21728-03-018 | 4210 x 1680 x 1435 | 1088 | 165 |
| 1.6 MT Спорт 21728-12-043 | 4210 x 1680 x 1435 | 1185 | 165 |
| 1.6 MT Люкс SE 21728-03-018 | 4210 x 1680 x 1435 | 1185 | 165 |
Размеры и масса Lada Priora 2008 5DR, 1 поколение, хэтчбек, 2172
Модель производилась с 02.2008 по 08.2014.
| Комплектация | Размер, мм | Вес, кг | Клиренс, мм |
| 1.6 MT Стандарт 21722-00-010 | 4210 x 1680 x 1435 | 1088 | 165 |
| 1.6 MT Норма 21723-01-035 | 4210 x 1680 x 1435 | 1088 | 165 |
| 1.6 MT Норма 21723-01-028/029 | 4210 x 1680 x 1435 | 1088 | 165 |
| 1.6 MT Норма 21723-01-021 | 4210 x 1680 x 1435 | 1088 | 165 |
1. 6 MT Норма 21723-01-011 6 MT Норма 21723-01-011 | 4210 x 1680 x 1435 | 1088 | 165 |
| 1.6 MT Норма 21723-01-012 | 4210 x 1680 x 1435 | 1088 | 165 |
| 1.6 MT Норма 21723-01-039 | 4210 x 1680 x 1435 | 1088 | 165 |
| 1.6 MT Норма 21723-71-039 | 4210 x 1680 x 1435 | 1088 | 165 |
| 1.6 MT Норма 21723-81-035 | 4210 x 1680 x 1435 | 1088 | 165 |
| 1.6 MT Норма 21723-01-033 | 4210 x 1680 x 1435 | 1088 | 165 |
| 1.6 MT Норма 21723-01-049 | 4210 x 1680 x 1435 | 1088 | 165 |
| 1.6 MT Норма 21723-81-045 | 4210 x 1680 x 1435 | 1088 | 165 |
| 1.6 MT Люкс 21723-03-031 | 4210 x 1680 x 1435 | 1088 | 165 |
| 1.6 MT Люкс 21723-03-041 | 4210 x 1680 x 1435 | 1088 | 165 |
| 1.6 MT Люкс 21723-03-043 | 4210 x 1680 x 1435 | 1088 | 165 |
1. 6 MT Люкс 21723-03-033 6 MT Люкс 21723-03-033 | 4210 x 1680 x 1435 | 1088 | 165 |
| 1.6 MT Люкс 21723-03-039 | 4210 x 1680 x 1435 | 1088 | 165 |
| 1.6 MT Люкс 21723-83-039 | 4210 x 1680 x 1435 | 1088 | 165 |
| 1.6 MT Люкс 21723-73-039 | 4210 x 1680 x 1435 | 1088 | 165 |
| 1.6 MT Люкс 21723-01-018 | 4210 x 1680 x 1435 | 1088 | 165 |
| 1.6 MT Люкс 21723-01-020 | 4210 x 1680 x 1435 | 1088 | 165 |
| 1.6 MT Стандарт 21722-00-040 | 4210 x 1680 x 1435 | 1163 | 165 |
| 1.6 MT Норма 21723-81-045 | 4210 x 1680 x 1435 | 1163 | 165 |
| 1.6 MT Норма 21723-01-041 | 4210 x 1680 x 1435 | 1163 | 165 |
| 1.6 MT Норма 21723-01-045 | 4210 x 1680 x 1435 | 1163 | 165 |
| 1.6 MT Норма 21723-01-047 | 4210 x 1680 x 1435 | 1163 | 165 |
1. 6 MT Норма 21723-01-049 6 MT Норма 21723-01-049 | 4210 x 1680 x 1435 | 1163 | 165 |
| 1.6 MT Норма 21723-21-042 | 4210 x 1680 x 1435 | 1163 | 165 |
| 1.6 MT Люкс SE 21723-23-042 | 4210 x 1680 x 1435 | 1163 | 165 |
| 1.6 MT Люкс SE 21723-03-049 | 4210 x 1680 x 1435 | 1163 | 165 |
| 1.6 MT Люкс SE 21723-13-041 | 4210 x 1680 x 1435 | 1163 | 165 |
| 1.6 MT Люкс SE 21723-03-043 | 4210 x 1680 x 1435 | 1163 | 165 |
| 1.6 MT Люкс SE 21723-03-041 | 4210 x 1680 x 1435 | 1163 | 165 |
| 1.6 MT Норма 21723-21-041 | 4210 x 1680 x 1435 | 1163 | 165 |
| 1.6 MT Норма 21723-21-043 | 4210 x 1680 x 1435 | 1163 | 165 |
| 1.6 MT Норма 21723-21-045 | 4210 x 1680 x 1435 | 1163 | 165 |
| 1.6 MT Норма 21723-21-047 | 4210 x 1680 x 1435 | 1163 | 165 |
1. 6 MT Люкс 21723-23-041 6 MT Люкс 21723-23-041 | 4210 x 1680 x 1435 | 1163 | 165 |
| 1.6 MT Люкс 21723-23-043 | 4210 x 1680 x 1435 | 1163 | 165 |
| 1.6 MT Люкс 21723-23-049 | 4210 x 1680 x 1435 | 1163 | 165 |
| 1.6 MT Люкс 21723-24-041 | 4210 x 1680 x 1435 | 1163 | 165 |
| 1.6 MT Люкс 21723-24-046 | 4210 x 1680 x 1435 | 1163 | 165 |
| 1.6 MT Люкс 21723-23-046 | 4210 x 1680 x 1435 | 1163 | 165 |
Размеры и масса Lada Priora 2008, 1 поколение, универсал, 2171
Модель производилась с 10.2008 по 09.2013.
| Комплектация | Размер, мм | Вес, кг | Клиренс, мм |
| 1.6 MT Норма 21713-01-49 | 4330 x 1680 x 1508 | 1088 | 165 |
| 1.6 MT Люкс 21713-03-49 | 4330 x 1680 x 1508 | 1088 | 165 |
1..jpg) 6 MT Люкс 21713-03-43 6 MT Люкс 21713-03-43 | 4330 x 1680 x 1508 | 1088 | 165 |
| 1.6 MT Люкс 21713-03-41 | 4330 x 1680 x 1508 | 1088 | 165 |
| 1.6 MT Люкс 21713-03-39 | 4330 x 1680 x 1508 | 1088 | 165 |
| 1.6 MT Норма 21713-71-039 | 4330 x 1680 x 1508 | 1088 | 165 |
| 1.6 MT Норма 21713-01-033 | 4330 x 1680 x 1508 | 1088 | 165 |
| 1.6 MT Люкс 21713-83-039 | 4330 x 1680 x 1508 | 1088 | 165 |
| 1.6 MT Люкс 21713-73-039 | 4330 x 1680 x 1508 | 1088 | 165 |
| 1.6 MT Норма 21713-81-035 | 4330 x 1680 x 1508 | 1088 | 165 |
| 1.6 MT Люкс 21713-01-020 | 4330 x 1680 x 1508 | 1088 | 165 |
| 1.6 MT Люкс 21713-01-018 | 4330 x 1680 x 1508 | 1088 | 165 |
| 1.6 MT Норма 21713-01-035 | 4330 x 1680 x 1508 | 1088 | 165 |
1. 6 MT Норма 21713-01-039 6 MT Норма 21713-01-039 | 4330 x 1680 x 1508 | 1088 | 165 |
| 1.6 MT Норма 21713-01-028/029 | 4330 x 1680 x 1508 | 1088 | 165 |
| 1.6 MT Норма 21713-01-021 | 4330 x 1680 x 1508 | 1088 | 165 |
| 1.6 MT Норма 21713-01-012 | 4330 x 1680 x 1508 | 1088 | 165 |
| 1.6 MT Норма 21713-21-042 | 4330 x 1680 x 1508 | 1088 | 165 |
| 1.6 MT Люкс SE 21713-23-042 | 4330 x 1680 x 1508 | 1088 | 165 |
| 1.6 MT Люкс SE 21713-03-049 | 4330 x 1680 x 1508 | 1088 | 165 |
| 1.6 MT Люкс SE 21713-03-043 | 4330 x 1680 x 1508 | 1088 | 165 |
| 1.6 MT Норма 21713-01-049 | 4330 x 1680 x 1508 | 1088 | 165 |
| 1.6 MT Норма 21713-01-047 | 4330 x 1680 x 1508 | 1088 | 165 |
| 1.6 MT Норма 21713-01-045 | 4330 x 1680 x 1508 | 1088 | 165 |
1. 6 MT Норма 21713-01-041 6 MT Норма 21713-01-041 | 4330 x 1680 x 1508 | 1088 | 165 |
| 1.6 MT Норма 21713-01-043 | 4330 x 1680 x 1508 | 1088 | 165 |
| 1.6 MT Люкс SE 21713-13-041 | 4330 x 1680 x 1508 | 1088 | 165 |
| 1.6 MT Люкс SE 21713-03-041 | 4330 x 1680 x 1508 | 1088 | 165 |
| 1.6 MT Норма 21713-21-045 | 4330 x 1680 x 1508 | 1088 | 165 |
| 1.6 MT Норма 21713-21-041 | 4330 x 1680 x 1508 | 1088 | 165 |
| 1.6 MT Норма 21713-21-043 | 4330 x 1680 x 1508 | 1088 | 165 |
| 1.6 MT Норма 21713-21-047 | 4330 x 1680 x 1508 | 1088 | 165 |
| 1.6 MT Люкс 21713-23-041 | 4330 x 1680 x 1508 | 1088 | 165 |
| 1.6 MT Люкс 21713-23-043 | 4330 x 1680 x 1508 | 1088 | 165 |
| 1.6 MT Люкс 21713-23-049 | 4330 x 1680 x 1508 | 1088 | 165 |
1. 6 MT Люкс 21713-24-041 6 MT Люкс 21713-24-041 | 4330 x 1680 x 1508 | 1088 | 165 |
| 1.6 MT Люкс 21713-23-046 | 4330 x 1680 x 1508 | 1088 | 165 |
| 1.6 MT Люкс 21713-24-046 | 4330 x 1680 x 1508 | 1088 | 165 |
Размеры и масса Lada Priora 2007, 1 поколение, седан, 2170
Модель производилась с 03.2007 по 07.2014. Читайте обзор Lada Priora 2007.
| Комплектация | Размер, мм | Вес, кг | Клиренс, мм |
| 1.6 MT Стандарт 21702-00-010 | 4350 x 1680 x 1420 | 1088 | 165 |
| 1.6 MT Норма 21703-71-039 | 4350 x 1680 x 1420 | 1088 | 165 |
| 1.6 MT Норма 21703-01-049 | 4350 x 1680 x 1420 | 1088 | 165 |
| 1.6 MT Норма 21703-01-045 | 4350 x 1680 x 1420 | 1088 | 165 |
| 1.6 MT Норма 21703-01-033 | 4350 x 1680 x 1420 | 1088 | 165 |
1. 6 MT Норма 21703-81-035 6 MT Норма 21703-81-035 | 4350 x 1680 x 1420 | 1088 | 165 |
| 1.6 MT Норма 21703-01-035 | 4350 x 1680 x 1420 | 1088 | 165 |
| 1.6 MT Норма 21703-01-032 | 4350 x 1680 x 1420 | 1088 | 165 |
| 1.6 MT Норма 21703-01-011 | 4350 x 1680 x 1420 | 1088 | 165 |
| 1.6 MT Норма 21703-01-012 | 4350 x 1680 x 1420 | 1088 | 165 |
| 1.6 MT Норма 21703-01-021 | 4350 x 1680 x 1420 | 1088 | 165 |
| 1.6 MT Норма 21703-01-028/029 | 4350 x 1680 x 1420 | 1088 | 165 |
| 1.6 MT Норма 21703-01-030 | 4350 x 1680 x 1420 | 1088 | 165 |
| 1.6 MT Норма 21703-01-039 | 4350 x 1680 x 1420 | 1088 | 165 |
| 1.6 MT Люкс 21703-03-020 | 4350 x 1680 x 1420 | 1088 | 165 |
| 1.6 MT Люкс 21703-03-018/019 | 4350 x 1680 x 1420 | 1088 | 165 |
1. 6 MT Люкс 21703-73-039 6 MT Люкс 21703-73-039 | 4350 x 1680 x 1420 | 1088 | 165 |
| 1.6 MT Люкс 21703-83-032 | 4350 x 1680 x 1420 | 1088 | 165 |
| 1.6 MT Люкс 21703-83-039 | 4350 x 1680 x 1420 | 1088 | 165 |
| 1.6 MT Люкс 21703-03-033 | 4350 x 1680 x 1420 | 1088 | 165 |
| 1.6 MT Люкс 21703-03-031 | 4350 x 1680 x 1420 | 1088 | 165 |
| 1.6 MT Люкс 21703-03-041 | 4350 x 1680 x 1420 | 1088 | 165 |
| 1.6 MT Люкс 21703-03-043 | 4350 x 1680 x 1420 | 1088 | 165 |
| 1.6 MT Люкс 21703-03-049 | 4350 x 1680 x 1420 | 1088 | 165 |
| 1.6 MT Норма 21703-01-041 | 4350 x 1680 x 1420 | 1088 | 165 |
| 1.6 MT Норма 21703-01-047 | 4350 x 1680 x 1420 | 1088 | 165 |
| 1.6 MT Норма 21703-71-049 | 4350 x 1680 x 1420 | 1088 | 165 |
1. 6 MT Норма 21703-21-042 6 MT Норма 21703-21-042 | 4350 x 1680 x 1420 | 1088 | 165 |
| 1.6 MT Люкс SE 21703-03-049 | 4350 x 1680 x 1420 | 1088 | 165 |
| 1.6 MT Люкс SE 21703-13-041 | 4350 x 1680 x 1420 | 1088 | 165 |
| 1.6 MT Люкс SE 21703-03-041 | 4350 x 1680 x 1420 | 1088 | 165 |
| 1.6 MT Люкс SE 21703-03-043 | 4350 x 1680 x 1420 | 1088 | 165 |
| 1.6 MT Норма 21703-21-041 | 4350 x 1680 x 1420 | 1088 | 165 |
| 1.6 MT Норма 21703-21-043 | 4350 x 1680 x 1420 | 1088 | 165 |
| 1.6 MT Норма 21703-21-045 | 4350 x 1680 x 1420 | 1088 | 165 |
| 1.6 MT Норма 21703-21-047 | 4350 x 1680 x 1420 | 1088 | 165 |
| 1.6 MT Люкс 21703-23-041 | 4350 x 1680 x 1420 | 1088 | 165 |
| 1.6 MT Люкс 21703-23-043 | 4350 x 1680 x 1420 | 1088 | 165 |
1. 6 MT Люкс 21703-23-049 6 MT Люкс 21703-23-049 | 4350 x 1680 x 1420 | 1088 | 165 |
| 1.6 MT Люкс 21703-24-041 | 4350 x 1680 x 1420 | 1088 | 165 |
| 1.6 MT Люкс 21703-24-046 | 4350 x 1680 x 1420 | 1088 | 165 |
| 1.6 MT Люкс 21703-23-046 | 4350 x 1680 x 1420 | 1088 | 165 |
| 1.6 MT Норма 21703-01-010 | 4350 x 1680 x 1420 | 1088 | 165 |
| 1.6 MT Норма 21703-01-018 | 4350 x 1680 x 1420 | 1088 | 165 |
| 1.6 MT Люкс 21703-02-018 | 4350 x 1680 x 1420 | 1088 | 165 |
| 1.6 MT Норма 21703-01-015 | 4350 x 1680 x 1420 | 1088 | 165 |
| 1.6 МТ Стандарт 21702-20-040 | 4350 x 1680 x 1420 | 1185 | 165 |
Похожие
Приора — орбитальная документация
Приора — орбитальная документация
- класс orbitize.
 priors.GaussianPrior( мю , сигма , no_negatives=True )[источник]
priors.GaussianPrior( мю , сигма , no_negatives=True )[источник] Приоритет Гаусса.
\[log(p(x|\sigma, \mu)) \propto \frac{(x — \mu)}{\sigma}\]
- Параметры
mu ( float ) – среднее значение распределения
сигма ( float ) – стандартное отклонение распределения
no_negatives ( bool ) — если True, то из
этот априор, и вероятность отрицательных значений будет равна 0 (по умолчанию: True).
(письменно) Сара Блант, 2018
- calculate_lnprob ( element_array ) [источник]
Вычислить логарифм (вероятность) массива чисел относительно распределения Гаусса.
Отрицательные числа возвращают вероятность -inf.- Параметры
element_array ( float или np.
array of float ) — массив чисел. Мы хотим
вероятность извлечения каждого из них из соответствующего гауссова
раздача- Возвращает
массив логарифмических (вероятностных) значений,
соответствует вероятности выпадения каждого из чисел
на входе element_array .- Тип возврата
пустой массив с плавающей запятой
- draw_samples( num_samples )[источник]
Возьмите положительные образцы из распределения Гаусса.
Отрицательные образцы не будут возвращены.- Параметры
num_samples ( float ) — количество сэмплов для генерации
- Возвращает
проб, взятых из соответствующих
Гауссово распределение. Массив имеет длину число_выборок .- Тип возврата
пустой массив с плавающей запятой
 priors.GaussianPrior( мю , сигма , no_negatives=True )[источник]
priors.GaussianPrior( мю , сигма , no_negatives=True )[источник]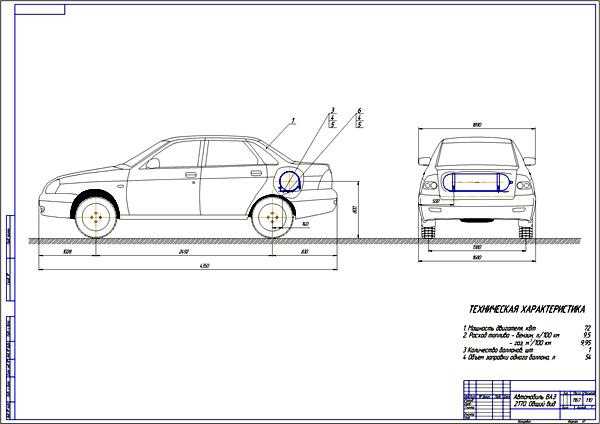 array of float ) — массив чисел. Мы хотим
array of float ) — массив чисел. Мы хотим- класс orbitize. priors.KDEPrior( gaussian_kde , total_params , bounds=[] , log_scale_arr=[] )[источник]
Предыдущая оценка плотности ядра Гаусса (KDE). Этот класс
оболочка для scipy.stats.gaussian_kde.- Параметры
gaussian_kde ( scipy.stats.gaussian_kde ) — scipy объект KDE, содержащий
KDE определяется пользователемtotal_params ( float ) — количество параметров в KDE
bounds ( array_like of bool , необязательный ) — границы для KDE, из которых проблема
возвращено -Infграниц – если True для параметра
параметр подходит для KDE в логарифмической шкале
Автор: Хорхе ЛЛоп-Сейсон, Сара Блант (2021)
- calculate_lnprob ( element_array ) [источник]
Вычислить журнал (вероятность) массива чисел относительно определенного KDE.
Отрицательные числа возвращают вероятность -inf.- Параметры
element_array ( float или np.array of float ) — массив чисел. Мы хотим
вероятность получения каждого из них из KDE.- Возвращает
массив логарифмических (вероятностных) значений,
соответствует вероятности выпадения каждого из чисел
на входе element_array .- Тип возврата
пустой массив с плавающей запятой
- draw_samples( num_samples )[источник]
Возьмите положительные образцы из KDE.
Отрицательные образцы не будут возвращены.- Параметры
num_samples ( float ) — количество сэмплов для генерации.
- Возвращает
образцов, взятых из KDE
распределение. Массив имеет длину num_samples .- Тип возврата
пустой массив с плавающей запятой
- increment_param_num()[источник]
Увеличьте индекс для оценки соответствующего параметра.
 priors.KDEPrior( gaussian_kde , total_params , bounds=[] , log_scale_arr=[] )[источник]
priors.KDEPrior( gaussian_kde , total_params , bounds=[] , log_scale_arr=[] )[источник]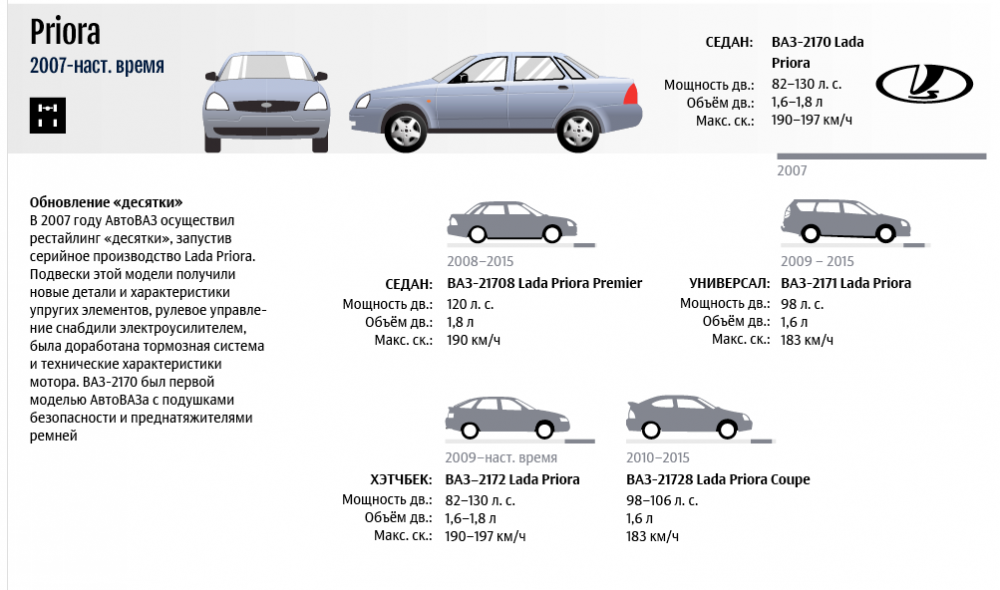

- класс orbitize.priors.LinearPrior( m , b )[источник]
Выбрать образцы из распределения вероятностей:
\[p(x) \свойство mx+b\]
, где m отрицательное, b положительное, а
диапазон [0,-б/м].- Параметры
- draw_samples( num_samples )[источник]
Выбрать образцы из нисходящего линейного распределения.
- Параметры
num_samples ( float ) — количество сэмплов для генерации
- Возвращает
образцов в диапазоне от [0, -b/m) в виде поплавков.
- Тип возврата
np.массив
- класс orbitize.priors.LogUniformPrior ( minval , maxval ) [источник]
Это распределение вероятностей \(p(x) \propto 1/x\)
Метод __init__ должен принимать значения «min» и «max».
распределения, которые соответствуют домену априора.
(Если это не реализовано, априор имеет сингулярность в 0 и бесконечную
интегральная вероятность).- Параметры
- calculate_lnprob ( element_array ) [источник]
Вычислить априорную вероятность каждого элемента, учитывая, что он взят из предшествующей Log-Uniofrm
- Параметры
element_array ( float или np.array of float ) — массив параметров для вычисления априорной вероятности
- Возвращает
массив априорных вероятностей
- Тип возврата
np.массив
- draw_samples( num_samples )[источник]
Возьмите образцы из этого распределения 1/x.
- Параметры
num_samples ( float ) — количество сэмплов для генерации
- Возвращает
образцов в диапазоне от [
minval,maxval) в виде поплавков.- Тип возврата
np.массив

- класс orbitize.priors.NearestNDInterpPrior ( interp_fct , total_params ) [источник]
Ближайший сосед интерп. Этот класс
оболочка для scipy.interpolate.NearestNDInterpolator.- Параметры
Написано: Хорхе ЛЛоп-Сейсон (2021)
- calculate_lnprob ( element_array ) [источник]
Вычислить журнал (вероятность) массива чисел относительно определенного ND
интерполятор. Отрицательные числа возвращают вероятность -inf.- Параметры
element_array ( float или np.array of float ) — массив чисел. Мы хотим
вероятность извлечения каждого из них из интерполятора ND.- Возвращает
массив логарифмических (вероятностных) значений,
соответствует вероятности выпадения каждого из чисел
на входе element_array .- Тип возврата
пустой массив с плавающей запятой
- draw_samples( num_samples )[источник]
Возьмите положительные образцы из интерполятора нейтральной плотности.
Отрицательные образцы не будут возвращены.- Параметры
num_samples ( float ) — количество сэмплов для генерации.
- Возвращает
образцов, взятых из интерполятора нейтральной плотности
распределение. Массив имеет длину num_samples .- Тип возврата
пустой массив с плавающей запятой
- increment_param_num()[источник]
Увеличьте индекс для оценки соответствующего параметра.
- класс orbitize.priors.Prior [источник]
Абстрактный базовый класс для предшествующих объектов.
Все предыдущие объекты должны наследоваться от этого класса.Написано: Сара Блант, 2018

- класс orbitize.priors.SinPrior[источник]
Это распределение вероятностей \(p(x) \propto sin(x)\)
Домен этого априора — [0,pi].
- вычислить_lnprob( element_array )[источник]
Вычислить априорную вероятность каждого элемента при условии, что он взят из априорного синуса
- Параметры
element_array ( float или np.array of float ) — массив параметров для вычисления априорной вероятности
- Возвращает
массив априорных вероятностей
- Тип возврата
np.массив
- draw_samples( num_samples )[источник]
Выбрать образцы из синусоидального распределения.
- Параметры
num_samples ( float ) — количество сэмплов для генерации
- Возвращает
выборок в диапазоне от [0, pi) в виде чисел с плавающей запятой.
- Тип возврата
np.массив
- класс orbitize.priors.UniformPrior( минимальное значение , максимальное значение ) [источник]
Это протоконстанта распределения вероятностей p(x).
- Параметры
- calculate_lnprob ( element_array ) [источник]
Вычислить априорную вероятность каждого элемента, учитывая, что он взят из этого однородного априора
- Параметры
element_array ( float или np.array of float ) — массив параметров для вычисления априорной вероятности
- Возвращает
массив априорных вероятностей
- Тип возврата
np.массив
- draw_samples( num_samples )[источник]
Возьмите образцы из этого равномерного распределения.
- Параметры
num_samples ( float ) — количество сэмплов для генерации
- Возвращает
выборок в диапазоне от [0, pi) в виде чисел с плавающей запятой.
- Тип возврата
np.массив
- orbitize.priors.all_lnpriors( params , Priors )[источник]
Вычисляет логарифм (априорную вероятность) набора параметров и список априорных значений
- Параметры
- Возвращает
априорная вероятность этого набора параметров
- Тип возврата
поплавок
Читать документы
v: последний
- Версии
- последний
- Загрузки
- HTML
- epub
- При прочтении документов
- Дом проекта
- Строит
EmpPrior: использование внешних эмпирических данных для информирования априорных значений длины ветвей для байесовской филогенетики | BMC Биоинформатика
- Программное обеспечение
- Открытый доступ
- Опубликовано:
- Джон Дж. Андерсен 1,2 ,
- Брэдли Дж. Нельсон 1,3 и
- Джереми М. Браун 1
Биоинформатика BMC
том 17 , номер статьи: 253 (2016)
Процитировать эту статью
1051 Доступ
7 Альтметрический
Сведения о показателях
Abstract
Background
Параметры длины ветвей являются центральным компонентом филогенетических моделей и представляют неотъемлемый биологический интерес. Априорные значения длины ветвей по умолчанию в некоторых байесовских филогенетических программах могут быть непреднамеренно информативными и приводить к необоснованным оценкам длин ветвей и деревьев. С другой стороны, априорные оценки могут быть неинформативными, но приводить к расплывчатым апостериорным оценкам. Несмотря на широкую доступность соответствующих наборов данных от других групп, биологи редко используют внешнюю информацию для определения априорных значений длины ветвей, специфичных для проводимого ими анализа.
Априорные значения длины ветвей по умолчанию в некоторых байесовских филогенетических программах могут быть непреднамеренно информативными и приводить к необоснованным оценкам длин ветвей и деревьев. С другой стороны, априорные оценки могут быть неинформативными, но приводить к расплывчатым апостериорным оценкам. Несмотря на широкую доступность соответствующих наборов данных от других групп, биологи редко используют внешнюю информацию для определения априорных значений длины ветвей, специфичных для проводимого ими анализа.
Результаты
Мы разработали программный пакет EmpPrior для облегчения сбора и включения релевантной внешней информации при установке априорных значений длины ветвей для филогенетики. EmpPrior эффективно запрашивает TreeBASE, чтобы найти данные, похожие на фокальные данные, с точки зрения таксономической и генетической выборки, и использует их для информирования априорных ветвей для фокального анализа. EmpPrior состоит из двух компонентов: EmpPrior-search, написанный на Java для запроса TreeBASE, и EmpPrior-fit, написанный на R для параметризации распределений длин ветвей. В примере анализа мы показываем, как EmpPrior делает возможным использование релевантных внешних данных и улучшает оценки длины дерева из основного набора данных.
В примере анализа мы показываем, как EmpPrior делает возможным использование релевантных внешних данных и улучшает оценки длины дерева из основного набора данных.
Заключение
EmpPrior прост в использовании, быстр и повышает как точность, так и воспроизводимость оценок длины ветвей во многих случаях. В то время как EmpPrior фокусируется на длине ветвей, используемая им стратегия может быть легко расширена для решения других проблем параметризации в филогенетике.
Предыстория
Априорные значения длины ветвей по умолчанию для байесовского филогенетического анализа могут привести к оценкам длин ветвей и деревьев, несовместимым с оценками максимального правдоподобия (MLE) [1–3]. Браун и др. [1] и Раннала и др. [3] исследовал эту проблему и выдвинул гипотезу, что для этих наборов данных плохо указанный априор может благоприятствовать неоправданно большим длинам ветвей и/или вызывать проблемы смешивания длин ветвей.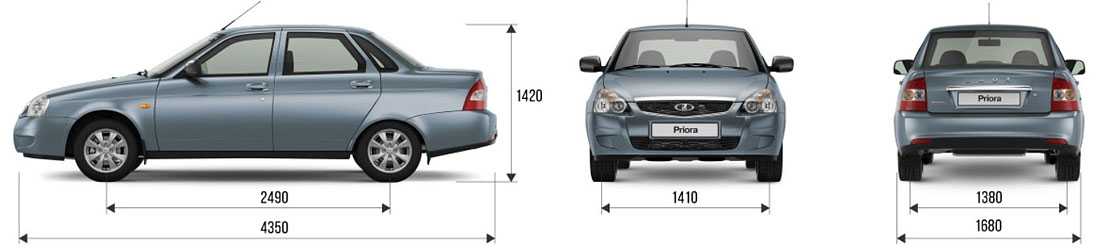 Такое поведение вызывает беспокойство, поскольку часто считается, что априорные значения по умолчанию оказывают минимальное влияние на апостериорные оценки. На практике спецификация неинформативных априорных значений может оказаться практически невозможной для многих параметров в филогенетике.
Такое поведение вызывает беспокойство, поскольку часто считается, что априорные значения по умолчанию оказывают минимальное влияние на апостериорные оценки. На практике спецификация неинформативных априорных значений может оказаться практически невозможной для многих параметров в филогенетике.
Коричневый и др. [1] предложил эмпирический байесовский подход для решения этих проблем, при котором априорные распределения параметризуются с использованием фокальных данных. Хотя этот метод обычно восстанавливает длины деревьев ML в получающихся достоверных интервалах, он подвергался критике за то, что он небайесовский и искусственно снижает неопределенность. Раннала и др. [3] и Zhang et al. [4], использование составного априорного алгоритма Дирихле для длин ветвей и деревьев, который обычно улучшает экспоненциальную априорную длину ветвей по умолчанию. Однако настройки по умолчанию не восстановили оценку ML для всех изученных наборов данных, что проблематично для неинформативных априорных значений.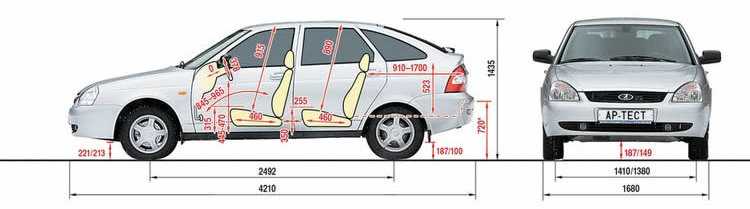
Для многих филогенетических вопросов доступны ранее собранные наборы данных, в которых используются одни и те же гены и образцы с таким же количеством таксонов в других кладах. Эти внешние данные можно использовать для информирования о предыдущих распределениях для анализа основных наборов данных. В некоторых предыдущих работах была предпринята попытка принципиального включения внешних молекулярных данных в филогенетический анализ [5], но исследование было ограничено и использовало стратегии иерархического моделирования, недоступные в настоящее время в популярных байесовских филогенетических пакетах программного обеспечения (например, MrBayes [6] и BEAST). [7]).
Использование внешних данных для параметризации априорных распределений в очаговом анализе в принципе относительно просто (рис. 1), но на практике возникает несколько процедурных проблем. Во-первых, к доступным филогенетическим базам данных (например, TreeBase и Dryad) может быть сложно обратиться, особенно в соответствии с критериями, которые могут быть важны для установления соответствия внешнего набора данных фокальному набору данных (например, количество отобранных таксонов).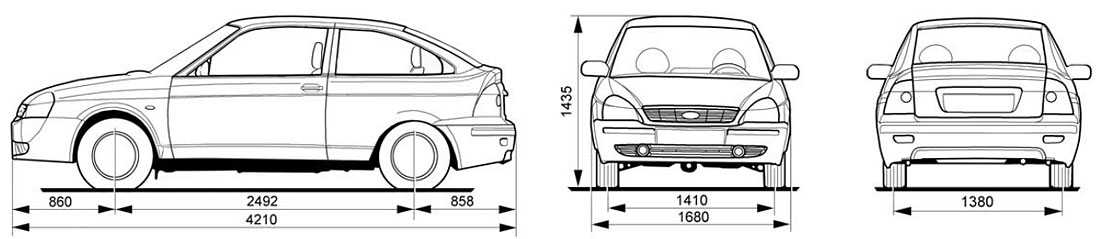 Кроме того, включение информации о длине ветвей неравномерно для депонированных деревьев. Длины ветвей могут отсутствовать полностью, они могут быть оценены с использованием объединенного набора данных или может быть использован неподходящий метод вывода. Во-вторых, после получения релевантных деревьев с длинами ветвей не существует программного обеспечения для оценки соответствующих значений параметров для распределений длин ветвей, которые используются в качестве априорных значений в большинстве байесовских филогенетических программ. Чтобы облегчить эти процедурные проблемы, мы разработали EmpPrior.
Кроме того, включение информации о длине ветвей неравномерно для депонированных деревьев. Длины ветвей могут отсутствовать полностью, они могут быть оценены с использованием объединенного набора данных или может быть использован неподходящий метод вывода. Во-вторых, после получения релевантных деревьев с длинами ветвей не существует программного обеспечения для оценки соответствующих значений параметров для распределений длин ветвей, которые используются в качестве априорных значений в большинстве байесовских филогенетических программ. Чтобы облегчить эти процедурные проблемы, мы разработали EmpPrior.
Рис. 1
Блок-схема для создания информированных априорных значений длины ветвей с помощью EmpPrior. EmpPrior-search запрашивает TreeBASE, чтобы найти данные, похожие на исходные данные. Затем внешние данные используются в качестве входных данных для поиска дерева максимального правдоподобия (ML). Распределения длин ветвей соответствуют деревьям ML в EmpPrior-fit, а оценки параметров используются для установки априорных значений для анализа фокусных данных
Полноразмерное изображение
суждение исследователя. В частности, для длин ветвей релевантные внешние наборы данных должны содержать последовательности с эволюционными свойствами, сходными с фокальным набором данных, и должны использовать аналогичные модели таксономической выборки как по количеству последовательностей, включенных в анализ, так и по распределению их родства. EmpPrior не избавляет от необходимости суждения в этих областях и не должен этого делать. Установление релевантности требует опыта и дает исследователям возможность применить свои знания о рассматриваемых таксонах для повышения точности и достоверности своих результатов. Скорее, EmpPrior служит набором инструментов для объединения доступной внешней информации, содержащейся как в существующих наборах данных, так и в опыте исследователя.
В частности, для длин ветвей релевантные внешние наборы данных должны содержать последовательности с эволюционными свойствами, сходными с фокальным набором данных, и должны использовать аналогичные модели таксономической выборки как по количеству последовательностей, включенных в анализ, так и по распределению их родства. EmpPrior не избавляет от необходимости суждения в этих областях и не должен этого делать. Установление релевантности требует опыта и дает исследователям возможность применить свои знания о рассматриваемых таксонах для повышения точности и достоверности своих результатов. Скорее, EmpPrior служит набором инструментов для объединения доступной внешней информации, содержащейся как в существующих наборах данных, так и в опыте исследователя.
Реализация
Мы разработали EmpPrior, чтобы упростить процесс поиска релевантных внешних наборов данных и их использования для установки информированных априорных значений длины ветвей в соответствии с доступными опциями в широко используемых байесовских филогенетических пакетах программного обеспечения. EmpPrior состоит из двух компонентов: EmpPrior-search и EmpPrior-fit (рис. 1). EmpPrior-search запрашивает TreeBASE с заданным пользователем именем гена (или другим выбранным пользователем поисковым термином) и ограничениями на размер набора данных, а затем анализирует и форматирует возвращенные файлы Nexus для вывода о филогении ML. EmpPrior-fit оптимизирует параметры распределения длин ветвей, используя филогении машинного обучения из внешних наборов данных. Результирующие оценки параметров могут быть скопированы непосредственно в априорные значения длины ветвей в байесовском филогенетическом программном обеспечении.
EmpPrior состоит из двух компонентов: EmpPrior-search и EmpPrior-fit (рис. 1). EmpPrior-search запрашивает TreeBASE с заданным пользователем именем гена (или другим выбранным пользователем поисковым термином) и ограничениями на размер набора данных, а затем анализирует и форматирует возвращенные файлы Nexus для вывода о филогении ML. EmpPrior-fit оптимизирует параметры распределения длин ветвей, используя филогении машинного обучения из внешних наборов данных. Результирующие оценки параметров могут быть скопированы непосредственно в априорные значения длины ветвей в байесовском филогенетическом программном обеспечении.
EmpPrior-search написан на Java, поэтому он не зависит от платформы и не требует внешних зависимостей. Пользователи могут предоставить EmpPrior-search список синонимов названий генов, и программа будет искать названия и рефераты в TreeBASE по этим терминам. В предварительных тестах поиск по заголовку и абстрактным полям давал наилучший компромисс, возвращая разумное количество наборов данных, сохраняя при этом их релевантность исходным условиям поиска. Файлы Nexus, связанные с соответствующими исследованиями, будут отфильтрованы в соответствии с введенными пользователем максимальными и минимальными значениями количества последовательностей. Затем EmpPrior-search будет обрабатывать файлы данных, заменяя коды неоднозначности TreeBASE (например, {A,C}) стандартными кодами Международного союза теоретической и прикладной химии (IUPAC) (например, M), удаляя все блоки Nexus, не связанные с выравниванием. и, если возможно, вырезание интересующего гена из объединенного набора данных. Файлы обработанных данных готовы к использованию в качестве входных данных для любой стандартной программы вывода филогении ML (например, Garli, RAxML, PhyML).
Файлы Nexus, связанные с соответствующими исследованиями, будут отфильтрованы в соответствии с введенными пользователем максимальными и минимальными значениями количества последовательностей. Затем EmpPrior-search будет обрабатывать файлы данных, заменяя коды неоднозначности TreeBASE (например, {A,C}) стандартными кодами Международного союза теоретической и прикладной химии (IUPAC) (например, M), удаляя все блоки Nexus, не связанные с выравниванием. и, если возможно, вырезание интересующего гена из объединенного набора данных. Файлы обработанных данных готовы к использованию в качестве входных данных для любой стандартной программы вывода филогении ML (например, Garli, RAxML, PhyML).
EmpPrior-search использует библиотеку классов Java Swing для создания графического пользовательского интерфейса (GUI; рис. 2), в котором пользователи могут указывать условия поиска для определения соответствующих наборов данных, доступных в TreeBase. После идентификации наборов данных с указанными пользователем именами генов в заголовках и аннотациях записей TreeBase EmpPrior-search использует независимые потоки для чтения каждого файла Nexus из TreeBase, используя соответствующий унифицированный указатель ресурсов (URL). После загрузки количество таксонов в каждом файле данных сравнивается с пользовательскими спецификациями, и наборы данных, выходящие за пределы допустимого диапазона, удаляются. Остальные файлы проверяются на наличие повторяющихся идентификаторов исследований, если один и тот же набор данных был возвращен поиском с разными синонимами имен генов, и дубликаты удаляются. Затем наборы данных переименовываются, чтобы указать как идентификатор исследования, так и имя гена, по которому они были идентифицированы. В случае дубликатов будет использоваться только первый синоним гена в списке, предоставленном пользователем. В ситуациях, когда заголовки и рефераты часто содержат несколько синонимов названий генов, будет загружено гораздо больше наборов данных, чем будет сохранено после постобработки. Тем не менее, EmpPrior-search обычно занимает всего несколько минут, чтобы завершить процесс загрузки и постобработки, даже при использовании нескольких синонимов для популярных генов. После загрузки файла и обработки с помощью EmpPrior-search пользователь должен будет принять решение о том, какие наборы данных относятся к фокальному набору данных, а затем выполнить филогенетический вывод ML, используя предпочитаемое им программное обеспечение.
После загрузки количество таксонов в каждом файле данных сравнивается с пользовательскими спецификациями, и наборы данных, выходящие за пределы допустимого диапазона, удаляются. Остальные файлы проверяются на наличие повторяющихся идентификаторов исследований, если один и тот же набор данных был возвращен поиском с разными синонимами имен генов, и дубликаты удаляются. Затем наборы данных переименовываются, чтобы указать как идентификатор исследования, так и имя гена, по которому они были идентифицированы. В случае дубликатов будет использоваться только первый синоним гена в списке, предоставленном пользователем. В ситуациях, когда заголовки и рефераты часто содержат несколько синонимов названий генов, будет загружено гораздо больше наборов данных, чем будет сохранено после постобработки. Тем не менее, EmpPrior-search обычно занимает всего несколько минут, чтобы завершить процесс загрузки и постобработки, даже при использовании нескольких синонимов для популярных генов. После загрузки файла и обработки с помощью EmpPrior-search пользователь должен будет принять решение о том, какие наборы данных относятся к фокальному набору данных, а затем выполнить филогенетический вывод ML, используя предпочитаемое им программное обеспечение.
Рис. 2
EmpPrior-search графический пользовательский интерфейс (GUI). Графический интерфейс EmpPrior-search позволяет пользователям указывать имя гена и ограничения на количество таксонов в ряде текстовых полей внизу. Эти ограничения помогают гарантировать, что наборы данных, возвращенные в результате поиска, могут предоставить релевантную информацию для анализа основных данных. Окно в середине графического интерфейса регистрирует информацию о ходе поиска в TreeBase и постобработке наборов данных. Индикатор выполнения вверху дает пользователям приблизительное представление о прогрессе EmpPrior-search. Необязательный этап постобработки можно включить с помощью переключателя внизу, в результате чего EmpPrior-search попытается извлечь интересующий ген из набора данных с несколькими генами. Из-за несоответствий в именовании генов и форматировании файла данных этот шаг может иногда давать ненадежные результаты. Пользователи должны всегда вручную проверять соответствующие наборы данных, чтобы убедиться, что они были проанализированы должным образом
Полноразмерное изображение
EmpPrior-fit написан на R, что делает оба компонента программной платформы независимыми.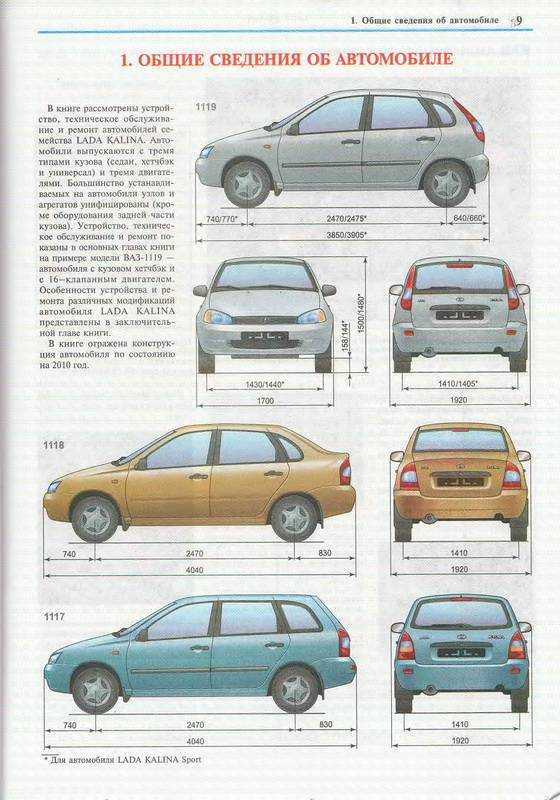 EmpPrior-fit собирает длины ветвей из филогений ML, выведенных с помощью внешних наборов данных (из любого источника), и предоставляет оценки параметров ML для общих априорных распределений длин ветвей (например, экспоненциальное и составное Дирихле). Для чтения деревьев EmpPrior-fit использует пакет R ape [8], а для оценки параметров машинного обучения — пакет bbmle [9]. Плотности вероятностей (то есть вероятности) для простых распределений (например, экспоненциальных) используют встроенную функциональность R. Вероятности для соединения Дирихле рассчитываются в соответствии с уравнением 36 из Rannala и др. [3]. О вероятностях сообщает EmpPrior-fit, хотя мы предупреждаем, что лучшее соответствие конкретного распределения длинам ветвей, оцененным на основе внешнего набора данных, не обязательно означает, что то же самое распределение имеет желаемые свойства, как и априорное для анализа фокального набора данных. Другие потенциальные распределения длин ветвей могут быть легко добавлены в EmpPrior-fit, если они представляют интерес или станут доступными в будущих реализациях байесовского филогенетического программного обеспечения.
EmpPrior-fit собирает длины ветвей из филогений ML, выведенных с помощью внешних наборов данных (из любого источника), и предоставляет оценки параметров ML для общих априорных распределений длин ветвей (например, экспоненциальное и составное Дирихле). Для чтения деревьев EmpPrior-fit использует пакет R ape [8], а для оценки параметров машинного обучения — пакет bbmle [9]. Плотности вероятностей (то есть вероятности) для простых распределений (например, экспоненциальных) используют встроенную функциональность R. Вероятности для соединения Дирихле рассчитываются в соответствии с уравнением 36 из Rannala и др. [3]. О вероятностях сообщает EmpPrior-fit, хотя мы предупреждаем, что лучшее соответствие конкретного распределения длинам ветвей, оцененным на основе внешнего набора данных, не обязательно означает, что то же самое распределение имеет желаемые свойства, как и априорное для анализа фокального набора данных. Другие потенциальные распределения длин ветвей могут быть легко добавлены в EmpPrior-fit, если они представляют интерес или станут доступными в будущих реализациях байесовского филогенетического программного обеспечения. Все вычисления, реализованные в EmpPrior-fit, выполняются быстро, поэтому даже большие наборы деревьев можно быстро обрабатывать с помощью скромных вычислительных ресурсов.
Все вычисления, реализованные в EmpPrior-fit, выполняются быстро, поэтому даже большие наборы деревьев можно быстро обрабатывать с помощью скромных вычислительных ресурсов.
Результаты и обсуждение
Мы провели EmpPrior-поиск по трем названиям генов, обычно встречающимся в филогеографических исследованиях (цитохром b [с использованием «cytb», «cyt_b», «cytochromeb» и «cytochrome_b»], цитохромоксидаза I [с использованием « COI» и «цитохром_оксидаза_I»] и рибулозо-бисфосфаткарбоксилаза [с использованием «rbcL»]), потому что анализы наборов данных, состоящих в основном из внутривидовых образцов, кажутся особенно чувствительными к выбранной длине ветви до этого. Три запуска проводились на ноутбуке MacBook Pro с процессором Intel Core i7 2,8 ГГц и заняли 19 часов.с (возврат 59 наборов данных), 134 с (возврат 93 наборов данных) и 135 с (возврат 111 наборов данных) соответственно.
Время, необходимое для вывода деревьев машинного обучения из внешних наборов данных, будет зависеть от размера набора данных и выбранного программного обеспечения, но всегда будет самым медленным шагом в информированной предварительной процедуре, как мы ее описали здесь.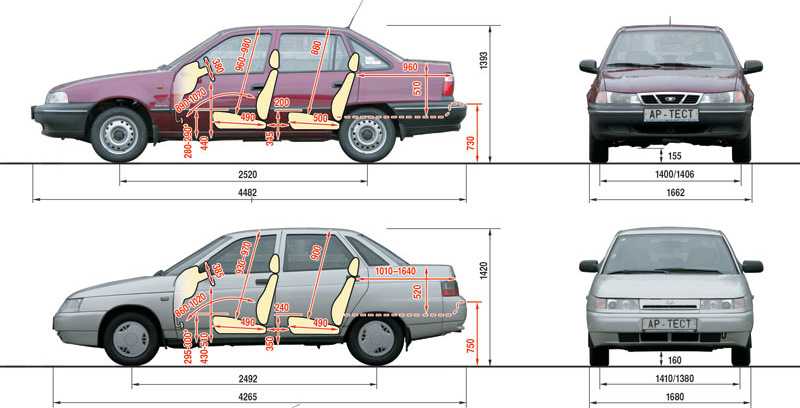 Удобно то, что деревья машинного обучения, которые мы используем для подгонки распределений длины ветвей, не требуют опорных значений. Избегая необходимости начальной загрузки или оценки апостериорных вероятностей, для внешних наборов данных время, необходимое для вывода деревьев ML, намного быстрее, чем для стандартного эмпирического анализа. Тем не менее, наш предварительный анализ показывает, что необходим тщательный вывод длин ветвей на основе модели, чтобы найти подходящие оценки параметров, которые хорошо работают в фокальном анализе.
Удобно то, что деревья машинного обучения, которые мы используем для подгонки распределений длины ветвей, не требуют опорных значений. Избегая необходимости начальной загрузки или оценки апостериорных вероятностей, для внешних наборов данных время, необходимое для вывода деревьев ML, намного быстрее, чем для стандартного эмпирического анализа. Тем не менее, наш предварительный анализ показывает, что необходим тщательный вывод длин ветвей на основе модели, чтобы найти подходящие оценки параметров, которые хорошо работают в фокальном анализе.
Подгонка распределений длин ветвей к деревьям ML с помощью EmpPrior-fit выполняется очень быстро (<1 с на дерево) и добавляет незначительное количество времени по сравнению с выводом дерева ML. Поверхности правдоподобия часто являются гладкими и унимодальными для интересующих параметров (рис. 3), поэтому EmpPrior-fit может надежно находить оценки максимального правдоподобия. Насколько нам известно, никакое другое программное обеспечение не предназначено специально для оценки параметров распределения длин ветвей, хотя числовые возможности, безусловно, существуют в других языках программирования и на других платформах.
Рис. 3
Логарифмические поверхности правдоподобия для c и α составного распределения длин ветвей Дирихле. Обе поверхности логарифмического правдоподобия были рассчитаны с использованием длин ветвей максимального правдоподобия (ML) на основе набора данных последовательностей цитохрома b и 16S альпийских тритонов ( Mesotriton alpestris ) с идентификатором TreeBase Study ID S1777 [11]. На левом графике показаны логарифмические правдоподобия, основанные на сложном распределении Дирихле [3] для различных значений отношения внутренних и внешних длин ветвей ( c ) со всеми остальными фиксированными параметрами. На правом графике показаны логарифмические правдоподобия для различных значений параметра концентрации ( α ) со всеми другими фиксированными параметрами. Пунктирная линия на каждом графике показывает оценку ML для каждого параметра, возвращенного EmpPrior-fit
Полноразмерное изображение
Всегда будет необходимо некоторое профессиональное суждение, чтобы выбрать, какой из наборов данных, возвращенных из EmpPrior-search, будет наиболее подходящим для информирования априорных используется при анализе фокального набора данных. В контексте байесовского анализа априорное состояние служит точкой, в которой такое суждение может быть естественно и надлежащим образом осуществлено. Мы считаем, что исследователи лучше подготовлены для оценки релевантности внешних наборов данных, которые затем используются для параметризации распределений длин ветвей, чем для непосредственного определения уместности оценок параметров. Эта разница в способности суждения может стать более выраженной по мере того, как предпочтительные априорные длины ветвей становятся более сложными (например, составное уравнение Дирихле) [3, 4] и используют распределения, менее знакомые многим биологам (например, распределение Дирихле). Осуществляя суждение при выборе внешних наборов данных, а затем подгоняя соответствующие распределения к этим данным, наш подход позволяет исследователям принципиальным образом определять информированные априорные данные.
В контексте байесовского анализа априорное состояние служит точкой, в которой такое суждение может быть естественно и надлежащим образом осуществлено. Мы считаем, что исследователи лучше подготовлены для оценки релевантности внешних наборов данных, которые затем используются для параметризации распределений длин ветвей, чем для непосредственного определения уместности оценок параметров. Эта разница в способности суждения может стать более выраженной по мере того, как предпочтительные априорные длины ветвей становятся более сложными (например, составное уравнение Дирихле) [3, 4] и используют распределения, менее знакомые многим биологам (например, распределение Дирихле). Осуществляя суждение при выборе внешних наборов данных, а затем подгоняя соответствующие распределения к этим данным, наш подход позволяет исследователям принципиальным образом определять информированные априорные данные.
Чтобы продемонстрировать полезность информированных априорных значений, параметризованных с использованием описанного нами подхода, EmpPrior был использован для установки информированных априорных значений длины ветвей для набора данных из 65 последовательностей мтДНК (COII и 16S) хрупкой звезды Astrotoma agassizii .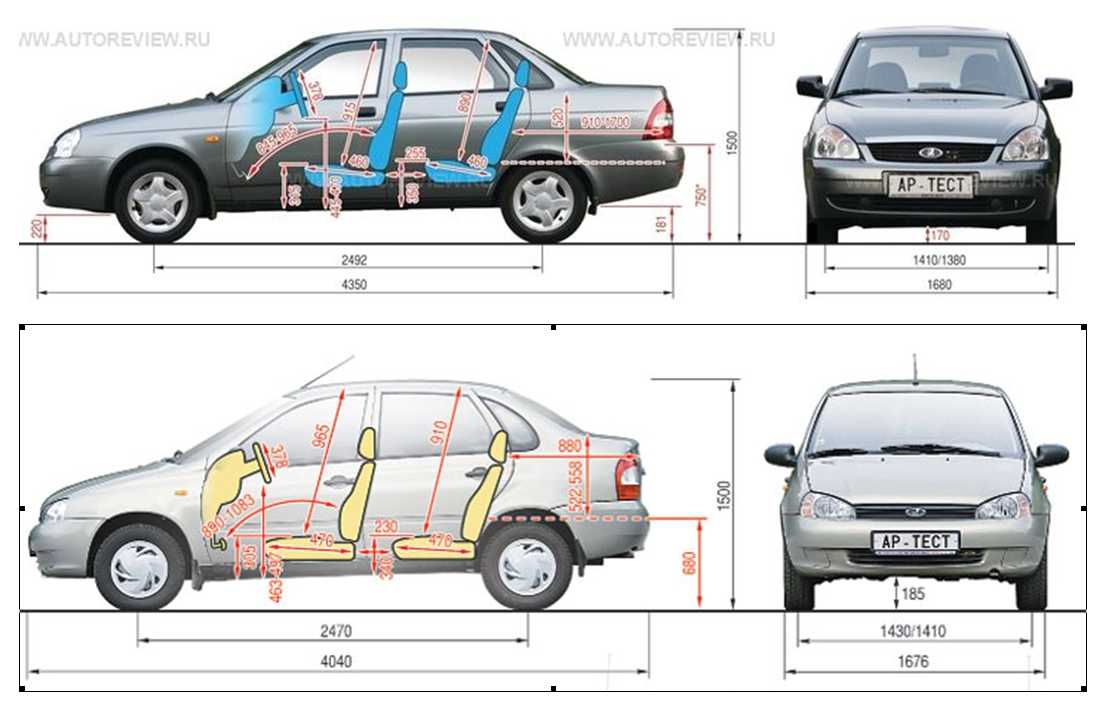 Ранее было показано, что этот набор данных возвращает ложные оценки длины дерева при экспоненциальной длине ветвления по умолчанию в MrBayes [2]. Программа MrBayes 3.2.2 [6] использовалась для оценки длины дерева как при стандартной, так и при информированной параметризации экспоненциальной и составной априорной длины ветвей Дирихле [3]. Информированные оценки параметров были основаны на двух соответствующих внешних наборах данных, каждый из которых содержал один из генов в основном наборе данных (COII: S2043, 16S: S1777). Эти наборы данных имели глубину и характер выборки (внутривидовой), аналогичные очаговым данным. Информированные значения параметров оценивались как для экспоненциального, так и для составного распределения Дирихле (с α и c оценены как по отдельности, так и вместе для соединения Дирихле). Как для предыдущих распределений, так и для обоих внешних наборов данных оценки длины дерева из информированных априорных данных были ближе к MLE, чем оценки по умолчанию (таблица 1).
Ранее было показано, что этот набор данных возвращает ложные оценки длины дерева при экспоненциальной длине ветвления по умолчанию в MrBayes [2]. Программа MrBayes 3.2.2 [6] использовалась для оценки длины дерева как при стандартной, так и при информированной параметризации экспоненциальной и составной априорной длины ветвей Дирихле [3]. Информированные оценки параметров были основаны на двух соответствующих внешних наборах данных, каждый из которых содержал один из генов в основном наборе данных (COII: S2043, 16S: S1777). Эти наборы данных имели глубину и характер выборки (внутривидовой), аналогичные очаговым данным. Информированные значения параметров оценивались как для экспоненциального, так и для составного распределения Дирихле (с α и c оценены как по отдельности, так и вместе для соединения Дирихле). Как для предыдущих распределений, так и для обоих внешних наборов данных оценки длины дерева из информированных априорных данных были ближе к MLE, чем оценки по умолчанию (таблица 1). Для составных априорных значений Дирихле с информированными значениями α 95% интервалов максимальной апостериорной плотности длины дерева включали MLE (таблица 1). В другом месте мы описываем более широкое тестирование информированного априорного подхода и обсуждаем его сильные и слабые стороны [10].
Для составных априорных значений Дирихле с информированными значениями α 95% интервалов максимальной апостериорной плотности длины дерева включали MLE (таблица 1). В другом месте мы описываем более широкое тестирование информированного априорного подхода и обсуждаем его сильные и слабые стороны [10].
Таблица 1 Оценки длины дерева по умолчанию и информированные оценки
Полноразмерная таблица
Хотя описанный нами информированный подход к установке априорных значений длины ветвей применялся в основном к наборам данных с небольшим числом локусов, его также можно использовать для большие наборы данных с одинаковыми уровнями расхождения по локусам (например, ультраконсервативные элементы). Фактически, такие большие наборы данных позволяют еще более прямое применение информированных априорных данных, если небольшое подмножество данных используется для информирования априорных значений, которые затем применяются для анализа оставшихся данных. Будущая работа с EmpPrior будет посвящена изучению эффективности этого подхода для наборов данных, созданных с помощью целевого захвата последовательности. Увеличение количества общедоступных множественных выравниваний последовательностей, созданных как с помощью методов Сэнгера, так и методов высокопроизводительного секвенирования, будет способствовать более широкому использованию информированных априорных значений длины ветвей и других интересующих параметров.
Будущая работа с EmpPrior будет посвящена изучению эффективности этого подхода для наборов данных, созданных с помощью целевого захвата последовательности. Увеличение количества общедоступных множественных выравниваний последовательностей, созданных как с помощью методов Сэнгера, так и методов высокопроизводительного секвенирования, будет способствовать более широкому использованию информированных априорных значений длины ветвей и других интересующих параметров.
Выводы
Используя внешние наборы данных с глубиной выборки (например, на уровне вида) и эволюционными свойствами, которые аналогичны фокальному набору данных, исследователи могут избежать цикличности эмпирических байесовских подходов и улучшить предыдущую производительность по умолчанию [10]. Несмотря на привлекательность этого подхода, несколько процедурных препятствий затрудняют его применение на практике. Мы разработали EmpPrior, чтобы помочь преодолеть эти препятствия, и показали, что он может повысить точность и достоверность оценок длины ветвей по сравнению с настройками по умолчанию популярного байесовского филогенетического программного обеспечения.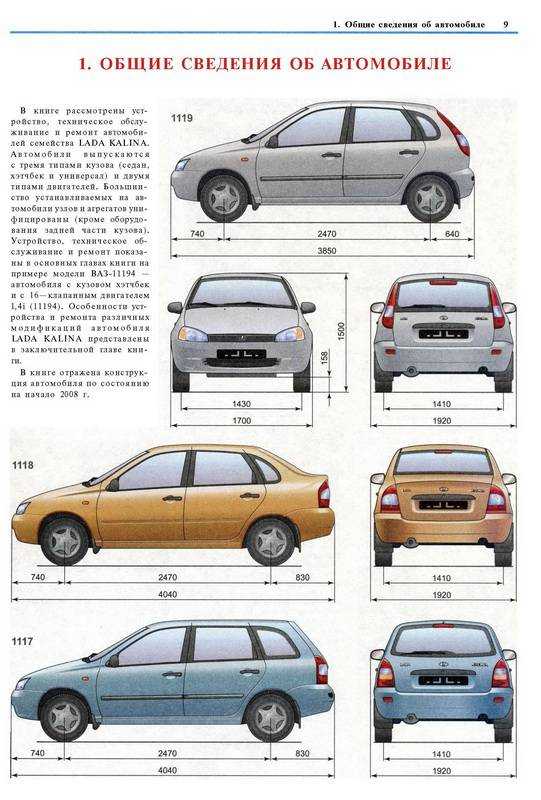 Мы надеемся, что информированные априоры найдут более широкое применение в байесовской филогенетике.
Мы надеемся, что информированные априоры найдут более широкое применение в байесовской филогенетике.
Наличие и требования
Название проекта: EmpPrior
Домашняя страница проекта :
https://github.com/jembrown/EmpPrior
Операционные системы: Независимость от платформы
Язык программирования : Java и R
Прочие требования: EmpPrior-search: Java версии 1.8; EmpPrior-fit: R версии 3.2, пакеты CRAN ape и bbmle.
Лицензия : GNU GPL v3
Любые ограничения для использования неакадемическими работниками : Нет
Сокращения
GUI, графический пользовательский интерфейс; IUPAC, Международный союз теоретической и прикладной химии; ML, максимальная вероятность; MLE, оценка максимального правдоподобия; URL, унифицированный указатель ресурса.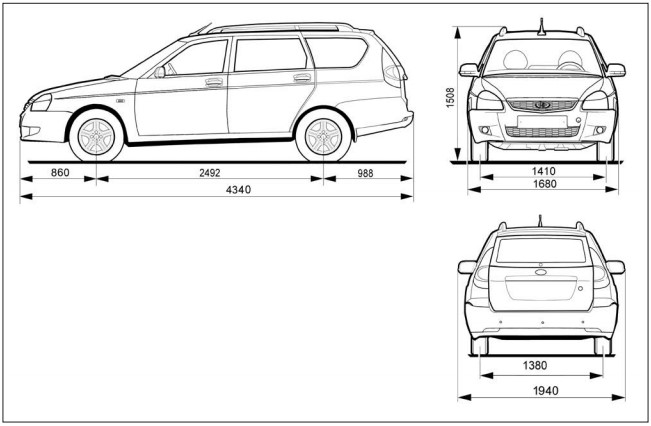
Ссылки
Браун Дж.М., Хедтке С.М., Леммон А.Р., Леммон Э.М. Когда деревья вырастают слишком длинными: исследование причин очень неточных байесовских оценок длины ветвей. Сист биол. 2010;59: 145–61.
Артикул
пабмедGoogle ученый
Маршалл, округ Колумбия. Загадочный провал разделенного байесовского филогенетического анализа: затерянный в стране длинных деревьев. Сист биол. 2010;59:108–17.
Артикул
пабмедGoogle ученый
Раннала Б., Чжу Т., Ян З. Парадокс хвоста, частичная идентифицируемость и влиятельные априоры в байесовском выводе длины ветви. Мол Биол Эвол. 2012;29: 325–35.
Артикул
КАС
пабмедGoogle ученый
Чжан С., Раннала Б.
, Ян З. Надежность составных априорных значений Дирихле для байесовского вывода длин ветвей. Сист биол. 2012;61:779–84.Артикул
пабмедGoogle ученый
Лян Л-Дж., Вайс Р.Э., Ределингс Б., Сушард М.А. Улучшение филогенетического анализа за счет включения дополнительной информации из баз данных генетических последовательностей. Биоинформатика. 2009 г.;25:2530–6.
Артикул
КАС
пабмед
ПабМед ЦентральныйGoogle ученый
Ронквист Ф., Тесленко М., Ван Дер Марк П., Айрес Д.Л., Дарлинг А., Хёна С., Ларгет Б., Лю Л., Сушард М.А., Хюльзенбек Дж.П. MrBayes 3.2: Эффективный байесовский филогенетический вывод и выбор модели в большом модельном пространстве. Сист биол. 2012; 61: 539–42.
Артикул
пабмед
ПабМед ЦентральныйGoogle ученый
 «>
«>Драммонд А.Дж., Рамбо А. ЗВЕРЬ: байесовский эволюционный анализ путем выборки деревьев. БМС Эвол Биол. 2007;7:214.
Артикул
пабмед
ПабМед ЦентральныйGoogle ученый
Paradis E, Claude J, Strimmer K. APE: Анализ филогенетики и эволюции на языке R. Биоинформатика. 2004; 20: 289–90.
Артикул
КАС
пабмедGoogle ученый
Bolker B. bmble: Инструменты для общей оценки максимального правдоподобия. Пакет R версии 1.0.17 основан на stats4 основной группы разработчиков R. 2014. Доступно по адресу: https://cran.r-project.org/web/packages/bbmle/.
Нельсон Б.Дж., Андерсен Дж.Дж., Браун Дж.М. Дефлирование деревьев: улучшение байесовских оценок длины ветвей с использованием информированных априорных значений. Сист биол. 2015;64:441–7.
Артикул
пабмедGoogle ученый
 «>
«>Сотиропулос К., Элефтеракос К., Джукич Г., Калезич М.Л., Легакис А., Полимени Р.М. Филогения и биогеография альпийского тритона Mesotriton alpestris (Salamandridae, Caudata), полученные на основе последовательностей мтДНК. Мол Филогенет Эвол. 2007; 45: 211–26.
Артикул
КАС
пабмедGoogle ученый
Хантер Р.Л., Галаныч К.М. Оценка связи в задумчивой хрупкой звезде Astrotoma agassizii через пролив Дрейка в Южном океане. Дж. Херед. 2008;99: 137–48.
Артикул
КАС
пабмедGoogle ученый
Цвикль DJ. Подходы генетического алгоритма для филогенетического анализа больших наборов данных биологических последовательностей по критерию максимального правдоподобия. Кандидат наук. Диссертация. Техасский университет в Остине. Остин: Техасский университет; 2006.
Google ученый
 , Ян З. Надежность составных априорных значений Дирихле для байесовского вывода длин ветвей. Сист биол. 2012;61:779–84.
, Ян З. Надежность составных априорных значений Дирихле для байесовского вывода длин ветвей. Сист биол. 2012;61:779–84.Скачать ссылки
Благодарности
Авторы выражают благодарность M.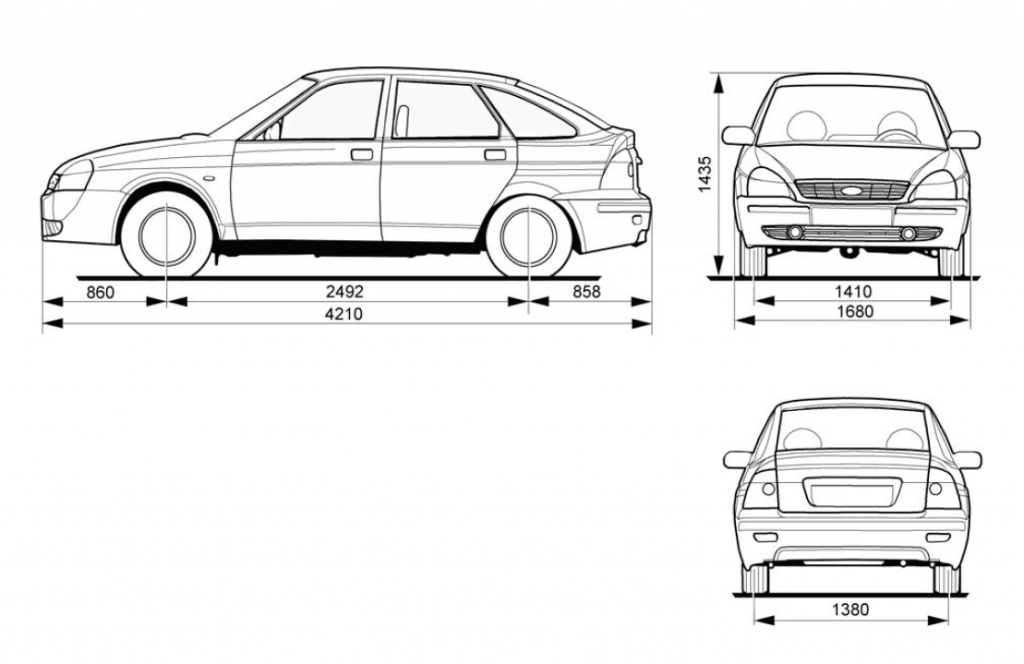 Holder, W. Ludt, M. Harvey, V. Doyle, B. Faircloth и анонимным рецензентам за полезные комментарии. Некоторые анализы проводились с использованием вычислительных ресурсов, предоставленных HPC@LSU (http://hpc.lsu.edu).
Holder, W. Ludt, M. Harvey, V. Doyle, B. Faircloth и анонимным рецензентам за полезные комментарии. Некоторые анализы проводились с использованием вычислительных ресурсов, предоставленных HPC@LSU (http://hpc.lsu.edu).
Финансирование
Эта работа была поддержана премией 2011-DN-BX-K534 от Национального института юстиции и стартовыми фондами Университета штата Луизиана для JMB.
Наличие данных и материалов
Программное обеспечение и руководство: https://github.com/jembrown/EmpPrior
Данные эмпирического примера: https://treebase.org/treebase-web/search/study/summary.html?id=2013
Вклад авторов
JJA, BJN и JMB принимали участие в разработке программного обеспечения и написании рукописи. JJA и JMB внесли свой вклад в код поиска EmpPrior. BJN и JMB внесли свой вклад в код EmpPrior-fit. Все авторы внесли свой вклад, прочитали и одобрили окончательную версию этой рукописи.
Конкурирующие интересы
Авторы заявляют, что у них нет конкурирующих интересов.
Согласие на публикацию
Неприменимо.
Одобрение этики и согласие на участие
Неприменимо.
Информация об авторе
Авторы и организации
Департамент биологических наук и Музей естественных наук, Университет штата Луизиана, 202 Life Sciences Building, Baton Rouge, LA, 70803, USA
John J. Andersen, Bradley J. Нельсон и Джереми М. Браун
Текущий адрес: IBM, 11501 Burnet Rd., Austin, TX, 78758, USA
John J. Andersen
Текущий адрес: Факультет геномных наук, Вашингтонский университет, Foege Building S-250, Seattle , WA, 98195, USA
Bradley J. Nelson
Авторы
- John J. Andersen
Просмотр публикаций автора
Вы также можете искать этого автора в
PubMed Google Scholar - Bradley J. Nelson
Просмотр публикаций автора
Вы также можете искать этого автора в
PubMed Google Scholar - Джереми М.
